Tuesday, February 2, 2016
Sleep vs Suspend vs Wait methods
sleep() is a static method that is used to send the calling thread into a non-runnable state for the given duration of time. The important part for this is recognizing the “calling thread”, which is actually the thread in which the sleep() method is invoked rather than the thread object which may (which is essentially a violation of Java standards) invoke this method. What this means is, while calling Thread.sleep(<duration in milliseconds>) is appropriate and will send the invoking thread to non-runnable state, but calling t.sleep(<duration in milliseconds>) is inappropriate as it would cause the thread in which this call appears to go to non-runnable state instead of the “t” thread whose object is invoking the method. While in “sleep”, the thread will keep all the monitor locks which it might be holding at the time of sleep invocation.
Monday, February 1, 2016
Concurrent Hash Map
ConcurrentHashMap is a hash table which supports complete concurrency for retrievals and updates.
ConcurrentHashMap follows the specifications of a Hashtable.
ConcurrentHashMap does not lock the entire collection for synchronization.
ConcurrentHashMap is a suited candidate collection when there are high number of updates and less number of read concurrently.
ConcurrentHashMap implements ConcurrentMap which lays the blue print for the concurrent operations. This was introduced part of the JDK 1.5 in the Java collections framework.
ConcurrentHashMap Initialization
ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel)
ConcurrentHashMap comes with multiple constructors and above being one among them.
initialCapacity is to fix the internal size of the collection.
Hash table density is decided based on the loadFactor. Now this is new, concurrencyLevel. By default ConcurrentHashMap allows 16 number of concurrent threads.
We can change this number using the concurrencyLevl argument. Most of the times 16 should be sufficient and playing with these number may cause undesirable performance issues. Know before you set these arguments.
Failsafe
ConcurrentHashMap does not throw ConcurrentModificationException if the underlying collection is modified during an iteration is in progress.
Iterators may not reflect the exact state of the collection if it is being modified concurrently. It may reflect the state when it was created and at some moment later. The fail-safe property is given a guarantee based on this.
Which One is Best?
ConcurrentHashMap can be considered as an alternative to Hashtable. It is a better in comparison with a Hashtable and a synchronized Map.
ConcurrentHashMap blocks only the parts as required and provides ultimate concurrency.
ConcurrentHashMap by default is separated into 16 regions and locks are applied. This default number can be set while initializing a ConcurrentHashMap instance.
Key Points to Remember on ConcurrentHashMap
- ConcurrentHashMap only locks a portion of the collection on update
- ConcurrentHashMap is better than Hashtable and synchronized Map.
- ConcurrentHashMap is failsafe does not throws ConcurrentModificationException.
- null is not allowed as a key or value in ConcurrentHashMap.
- Level of concurrency can be chosen by the programmer on a ConcurrentHashMap while initializing it.
ConcurrentHashMap Example
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample {
public static void main(String[] args) {
ConcurrentHashMap concurrentHashMap = new ConcurrentHashMap();
concurrentHashMap.put("A","Apple");
concurrentHashMap.put("B","Blackberry");
for (Map.Entry e : concurrentHashMap.entrySet()) {
System.out.println(e.getKey() + " = " + e.getValue());
}
}
}
Fork and Join (J7)
ForkJoinPool was added to Java in Java 7.
The
ForkJoinPool is similar to the Java Executor Service but with one difference.
The
ForkJoinPool makes it easy for tasks to split their work up into smaller tasks which are then submitted to the ForkJoinPool too.
Tasks can keep splitting their work into smaller sub tasks for as long as it makes to split up the task. It may sound a bit abstract, so in this fork and join tutorial I will explain how the
ForkJoinPool works, and how splitting tasks up work.Fork and Join Explained
Before we look at the
ForkJoinPool I want to explain how the fork and join principle works in general.
The fork and join principle consists of two steps which are performed recursively. These two steps are the fork step and the join step.
Fork
A task that uses the fork and join principle can fork (split) itself into smaller subtasks which can be executed concurrently. This is illustrated in the diagram below:
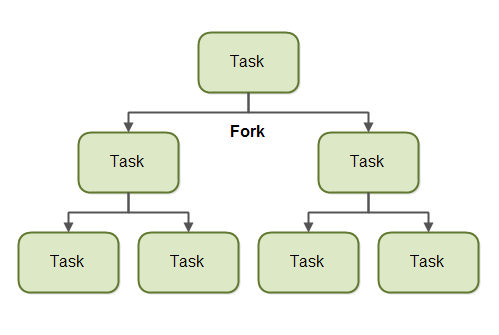
By splitting itself up into subtasks, each subtask can be executed in parallel by different CPUs, or different threads on the same CPU.
A task only splits itself up into subtasks if the work the task was given is large enough for this to make sense. There is an overhead to splitting up a task into subtasks, so for small amounts of work this overhead may be greater than the speedup achieved by executing subtasks concurrently.
The limit for when it makes sense to fork a task into subtasks is also called a threshold. It is up to each task to decide on a sensible threshold. It depends very much on the kind of work being done.
Join
When a task has split itself up into subtasks, the task waits until the subtasks have finished executing.
Once the subtasks have finished executing, the task may join (merge) all the results into one result. This is illustrated in the diagram below:
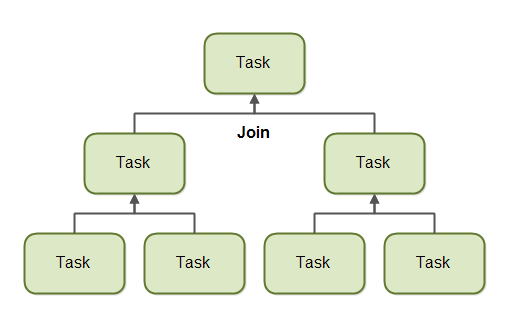
Of course, not all types of tasks may return a result. If the tasks do not return a result then a task just waits for its subtasks to complete. No result merging takes place then.
The ForkJoinPool
The
ForkJoinPool is a special thread pool which is designed to work well with fork-and-join task splitting. The ForkJoinPool located in the java.util.concurrent package, so the full class name isjava.util.concurrent.ForkJoinPool.Creating a ForkJoinPool
You create a
ForkJoinPool using its constructor. As a parameter to the ForkJoinPool constructor you pass the indicated level of parallelism you desire. The parallelism level indicates how many threads or CPUs you want to work concurrently on on tasks passed to the ForkJoinPool. Here is a ForkJoinPool creation example:ForkJoinPool forkJoinPool = new ForkJoinPool(4);
This example creates a
ForkJoinPool with a parallelism level of 4.Submitting Tasks to the ForkJoinPool
You submit tasks to a
ForkJoinPool similarly to how you submit tasks to an ExecutorService. You can submit two types of tasks. A task that does not return any result (an "action"), and a task which does return a result (a "task"). These two types of tasks are represented by the RecursiveAction and RecursiveTaskclasses. How to use both of these tasks and how to submit them will be covered in the following sections.RecursiveAction
A
RecursiveAction is a task which does not return any value. It just does some work, e.g. writing data to disk, and then exits.
A
RecursiveAction may still need to break up its work into smaller chunks which can be executed by independent threads or CPUs.
You implement a
RecursiveAction by subclassing it. Here is a RecursiveAction example:import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.RecursiveAction;
public class MyRecursiveAction extends RecursiveAction {
private long workLoad = 0;
public MyRecursiveAction(long workLoad) {
this.workLoad = workLoad;
}
@Override
protected void compute() {
//if work is above threshold, break tasks up into smaller tasks
if(this.workLoad > 16) {
System.out.println("Splitting workLoad : " + this.workLoad);
List<MyRecursiveAction> subtasks =
new ArrayList<MyRecursiveAction>();
subtasks.addAll(createSubtasks());
for(RecursiveAction subtask : subtasks){
subtask.fork();
}
} else {
System.out.println("Doing workLoad myself: " + this.workLoad);
}
}
private List<MyRecursiveAction> createSubtasks() {
List<MyRecursiveAction> subtasks =
new ArrayList<MyRecursiveAction>();
MyRecursiveAction subtask1 = new MyRecursiveAction(this.workLoad / 2);
MyRecursiveAction subtask2 = new MyRecursiveAction(this.workLoad / 2);
subtasks.add(subtask1);
subtasks.add(subtask2);
return subtasks;
}
}
This example is very simplified. The
MyRecursiveAction simply takes a fictive workLoad as parameter to its constructor. If the workLoad is above a certain threshold, the work is split into subtasks which are also scheduled for execution (via the .fork() method of the subtasks. If the workLoad is below a certain threshold then the work is carried out by the MyRecursiveAction itself.
You can schedule a
MyRecursiveAction for execution like this:MyRecursiveAction myRecursiveAction = new MyRecursiveAction(24);
forkJoinPool.invoke(myRecursiveAction);
RecursiveTask
A
RecursiveTask is a task that returns a result. It may split its work up into smaller tasks, and merge the result of these smaller tasks into a collective result.
The splitting and merging may take place on several levels. Here is a
RecursiveTask example:import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.RecursiveTask;
public class MyRecursiveTask extends RecursiveTask<Long> {
private long workLoad = 0;
public MyRecursiveTask(long workLoad) {
this.workLoad = workLoad;
}
protected Long compute() {
//if work is above threshold, break tasks up into smaller tasks
if(this.workLoad > 16) {
System.out.println("Splitting workLoad : " + this.workLoad);
List<MyRecursiveTask> subtasks =
new ArrayList<MyRecursiveTask>();
subtasks.addAll(createSubtasks());
for(MyRecursiveTask subtask : subtasks){
subtask.fork();
}
long result = 0;
for(MyRecursiveTask subtask : subtasks) {
result += subtask.join();
}
return result;
} else {
System.out.println("Doing workLoad myself: " + this.workLoad);
return workLoad * 3;
}
}
private List<MyRecursiveTask> createSubtasks() {
List<MyRecursiveTask> subtasks =
new ArrayList<MyRecursiveTask>();
MyRecursiveTask subtask1 = new MyRecursiveTask(this.workLoad / 2);
MyRecursiveTask subtask2 = new MyRecursiveTask(this.workLoad / 2);
subtasks.add(subtask1);
subtasks.add(subtask2);
return subtasks;
}
}
This example is similar to the
RecursiveAction example except it returns a result. The class MyRecursiveTaskextends RecursiveTask<Long> which means that the result returned from the task is a Long .
The
MyRecursiveTask example also breaks the work down into subtasks, and schedules these subtasks for execution using their fork() method.
Additionally, this example then receives the result returned by each subtask by calling the
join() method of each subtask. The subtask results are merged into a bigger result which is then returned. This kind of joining / mergining of subtask results may occur recursively for several levels of recursion.
You can schedule a
RecursiveTask like this:MyRecursiveTask myRecursiveTask = new MyRecursiveTask(128);
long mergedResult = forkJoinPool.invoke(myRecursiveTask);
System.out.println("mergedResult = " + mergedResult);
Notice how you get the final result out from the
ForkJoinPool.invoke() method call.Semaphore
A semaphore in Computer Science is analogous to a Guard at the entrance of a building.
However, this guard takes into account the number of people already entered into the building.
At any given time, there can be only a fixed amount of people inside the building.
When a person leaves the building, the guard allows a new person to enter the building.
In computer science realm, this sort of guard is called a Semaphore. The concept of Semaphore was invented by Edsger Dijkstra in 1965.
The semaphores in computer science can be broadly classified as :
- Binary Semaphore
- Counting Semaphore
Binary Semaphore has only two states on and off(lock/unlock).(can be implemented in Java by initializing Semaphore to size 1.)
The java.util.concurrent.Semaphore Class implements a counting Semaphore.
Features of Semaphore Class in Java
The Semaphore Class constructor takes a int parameter, which represents the number of virtual permits the corresponding semaphore object will allow.
The semaphore has two main methods that are used to acquire() and release() locks.
The Semaphore Class also supports Fairness setting by the boolean fair parameter. However, the fairness leads to reduced application throughput and as such should be used sparingly.
The Semaphore Class also supports non-blocking methods like tryacquire() and tryacquire(int permits).
Example,
import java.util.concurrent.Semaphore;
public class SemaphoreDemo {
Semaphore semaphore = new Semaphore(10);
public void printLock() {
try {
semaphore.acquire();
System.out.println("Locks acquired");
System.out.println("Locks remaining >> "
+ semaphore.availablePermits());
} catch (InterruptedException ie) {
ie.printStackTrace();
} finally {
semaphore.release();
System.out.println("Locks Released");
}
}
public static void main(String[] args) {
final SemaphoreDemo semaphoreDemo = new SemaphoreDemo();
Thread thread = new Thread() {
@Override
public void run() {
semaphoreDemo.printLock();
}
};
thread.start();
}
}
OUTPUT
Locks acquired
Locks remaining >> 9
Locks Released
Futures and Callables
The executor framework presented in the last chapter works with Runnable objects.
Unfortunately a Runnable cannot return a result to the caller.
In case you expect your threads to return a computed result you can use java.util.concurrent.Callable.
The Callable object allows to return values after completion.
The Callable object uses generics to define the type of object which is returned.
If you submit a Callable object to an Executor the framework returns an object of type java.util.concurrent.Future.
Future exposes methods allowing a client to monitor the progress of a task being executed by a different thread. Therefore a Future object can be used to check the status of a Callable and to retrieve the result from the Callable.
On the Executor you can use the method submit to submit a Callable and to get a future. To retrieve the result of the future use the get() method.
Example
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
Thread.sleep(1000);
//return the thread name executing this callable task
return Thread.currentThread().getName();
}
public static void main(String args[]){
//Get ExecutorService from Executors utility class, thread pool size is 10
ExecutorService executor = Executors.newFixedThreadPool(10);
//create a list to hold the Future object associated with Callable
List<Future<String>> list = new ArrayList<Future<String>>();
//Create MyCallable instance
Callable<String> callable = new MyCallable();
for(int i=0; i< 100; i++){
//submit Callable tasks to be executed by thread pool
Future<String> future = executor.submit(callable);
//add Future to the list, we can get return value using Future
list.add(future);
}
for(Future<String> fut : list){
try {
//print the return value of Future, notice the output delay in console
// because Future.get() waits for task to get completed
System.out.println(new Date()+ "::"+fut.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
//shut down the executor service now
executor.shutdown();
}
}
Once we execute the above program, you will notice the delay in output because Future get() method waits for the callable task to complete. Also notice that there are only 10 threads executing these tasks.
Here is snippet of the output of above program.
Mon Dec 31 20:40:15 PST 2012::pool-1-thread-1
Mon Dec 31 20:40:16 PST 2012::pool-1-thread-2
Mon Dec 31 20:40:16 PST 2012::pool-1-thread-3
Mon Dec 31 20:40:16 PST 2012::pool-1-thread-4
Mon Dec 31 20:40:16 PST 2012::pool-1-thread-5
Mon Dec 31 20:40:16 PST 2012::pool-1-thread-6
Mon Dec 31 20:40:16 PST 2012::pool-1-thread-7
Mon Dec 31 20:40:16 PST 2012::pool-1-thread-8
Mon Dec 31 20:40:16 PST 2012::pool-1-thread-9
Mon Dec 31 20:40:16 PST 2012::pool-1-thread-10
Mon Dec 31 20:40:16 PST 2012::pool-1-thread-2
...
Drawbacks with Futures and Callbacks
The Future interface is limited as a model of asynchronously executed tasks.
While Future allows a client to query a Callable task for its result, it does not provide the option to register a callback method, which would allow to notified once a task is done.
In Java 5 you could use ExecutorCompletionService for this purpose but as of Java 8 you can use the CompletableFuture interface which allows to provide a callback interface which is called once a task is completed.
Note:
CompletableFuture extends the functionality of the Future interface with the possibility to notify callbacks once a task is done.
This callback can be executed in another thread as the thread in which the CompletableFuture is executed.
Executor Framework
Threads pools with the Executor Framework
Thread pools manage a pool of worker threads.
The thread pools contains a work queue which holds tasks waiting to get executed.
A thread pool can be described as a collection of Runnable objects (work queue) and a connections of running threads.
These threads are constantly running and are checking the work query for new work.
If there is new work to be done they execute this Runnable. The Thread class itself provides a method, e.g. execute(Runnable r) to add a new Runnable object to the work queue.
The Executor framework provides example implementation of the java.util.concurrent.Executor interface, e.g. Executors.newFixedThreadPool(int n) which will create n worker threads. The ExecutorService adds life cycle methods to the Executor, which allows to shut down the Executor and to wait for termination.
Tip
If you want to use one thread pool with one thread which executes several runnables you can use the Executors.newSingleThreadExecutor() method.
Example,
public class WorkerThread implements Runnable {
private String command;
public WorkerThread(String s){
this.command=s;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+' Start. Command = '+command);
processCommand();
System.out.println(Thread.currentThread().getName()+' End.');
}
private void processCommand() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public String toString(){
return this.command;
}
}
Here is the test program where we are creating fixed thread pool from Executors framework.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class SimpleThreadPool {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
Runnable worker = new WorkerThread('' + i);
executor.execute(worker);
}
executor.shutdown();
while (!executor.isTerminated()) {
}
System.out.println('Finished all threads');
}
}
In above program, we are creating fixed size thread pool of 5 worker threads.
Then we are submitting 10 jobs to this pool, since the pool size is 5, it will start working on 5 jobs and other jobs will be in wait state, as soon as one of the job is finished, another job from the wait queue will be picked up by worker thread and get’s executed.
Here is the output of the above program.
pool-1-thread-2 Start. Command = 1
pool-1-thread-4 Start. Command = 3
pool-1-thread-1 Start. Command = 0
pool-1-thread-3 Start. Command = 2
pool-1-thread-5 Start. Command = 4
pool-1-thread-4 End.
pool-1-thread-5 End.
pool-1-thread-1 End.
pool-1-thread-3 End.
pool-1-thread-3 Start. Command = 8
pool-1-thread-2 End.
pool-1-thread-2 Start. Command = 9
pool-1-thread-1 Start. Command = 7
pool-1-thread-5 Start. Command = 6
pool-1-thread-4 Start. Command = 5
pool-1-thread-2 End.
pool-1-thread-4 End.
pool-1-thread-3 End.
pool-1-thread-5 End.
pool-1-thread-1 End.
Finished all threads
Volatile
If a variable is declared with the volatile keyword then it is guaranteed that any thread that reads the field will see the most recently written value.
The volatile keyword will not perform any mutual exclusive lock on the variable.
Volatile keyword in Java is used as an indicator to Java compiler and Thread that do not cache value of this variable and always read it from main memory.
The Volatile variable Example in Java
To Understand example of volatile keyword in java.let’s go back to Singleton pattern in Java and see double checked locking in Singleton with Volatile and without volatile keyword in java.
public class Singleton {
private static volatile Singleton _instance; //volatile variable
public static Singleton getInstance(){
if(_instance == null){
synchronized(Singleton.class){
if(_instance == null)
_instance = new Singleton();
}
}
return _instance;
}
If you look at the code carefully you will be able to figure out:
1) We are only creating instance one time
2) We are creating instance lazily at the time of first request comes.
If we do not make the _instance variable volatile than the Thread which is creating instance of Singleton is not able to communicate other thread, that instance has been created until it comes out of the Singleton block, so if Thread A is creating Singleton instance and just after creation lost the CPU, all other thread will not be able to see value of _instance as not null and they will believe its still NULL.

Why ?
Because reader threads are not doing any locking and until writer thread comes out of synchronized block, memory will not be synchronized and value of _instance will not be updated in main memory.
With Volatile keyword in Java this is handled by Java himself and such updates will be visible by all reader threads.
When to use Volatile variable in Java
- You can use Volatile variable, if you want to read and write long and double variable atomically.
- long and double both are 64 bit data type and by default writing of long and double is not atomic and platform dependence.
- Volatile variable can be used as an alternative way of achieving synchronization in Java in some cases, like Visibility. with volatile variable its guaranteed that all reader thread will see updated value of volatile variable once write operation completed, without volatile keyword different reader thread may see different values.
- volatile variable can be used to inform compiler that a particular field is subject to be accessed by multiple threads, which will prevent compiler from doing any reordering or any kind of optimization which is not desirable in multi-threaded environment. Without volatile variable compiler can re-order the code, free to cache value of volatile variable instead of always reading from main memory. like following example without volatile variable may result in infinite loop
private boolean isActive = thread;
public void printMessage(){
while(isActive){
System.out.println("Thread is Active");
}
}
without volatile modifier its not guaranteed that one Thread see the updated value of isActive from other thread. compiler is also free to cache value of isActive instead of reading it from main memory in every iteration. By making isActive a volatile variable you avoid these issue.
- Another place where volatile variable can be used is to fixing double checked locking in Singleton pattern
Important points on Volatile keyword in Java
1. The volatile keyword in Java is only application to variable and using volatile keyword with class and method is illegal.
2. volatile keyword in Java guarantees that value of volatile variable will always be read from main memory and not from Thread's local cache.
3. In Java reads and writes are atomic for all variables declared using Java volatile keyword (including long and double variables).
4. Using volatile keyword in Java on variables reduces the risk of memory consistency errors, because any write to a volatile variable in Java establishes a happens-before relationship with subsequent reads of that same variable.
5. From Java 5 changes to a volatile variable are always visible to other threads. What’s more it also means that when a thread reads a volatile variable in Java, it sees not just the latest change to the volatile variable but also the side effects of the code that led up the change.
6. Reads and writes are atomic for reference variables are for most primitive variables (all types except long and double) even without use of volatile keyword in Java.
7. An access to a volatile variable in Java never has chance to block, since we are only doing a simple read or write, so unlike a synchronized block we will never hold on to any lock or wait for any lock.
8. Java volatile variable that is an object reference may be null.
9. Java volatile keyword doesn't means atomic, its common misconception that after declaring volatile ++ will be atomic, to make the operation atomic you still need to ensure exclusive access using synchronized method or block in Java.
10. If a variable is not shared between multiple threads no need to use volatile keyword with that variable.
Difference between synchronized and volatile keyword in Java
1. The volatile keyword in Java is a field modifier, while synchronized modifies code blocks and methods.
2. Synchronized obtains and releases lock on monitor’s Java volatile keyword doesn't require that.
3. Threads in Java can be blocked for waiting any monitor in case of synchronized, that is not the case with volatile keyword in Java.
4. Synchronized method affects performance more than volatile keyword in Java.
5. Since volatile keyword in Java only synchronizes the value of one variable between Thread memory and "main" memory while synchronized synchronizes the value of all variable between thread memory and "main" memory and locks and releases a monitor to boot.
Due to this reason synchronized keyword in Java is likely to have more overhead than volatile.
Due to this reason synchronized keyword in Java is likely to have more overhead than volatile.
6. You can not synchronize on null object but your volatile variable in Java could be null.
7. From Java 5 writing into a volatile field has the same memory effect as a monitor release, and reading from a volatile field has the same memory effect as a monitor acquire.
Subscribe to:
Posts (Atom)